

Rob Moore
The NCAA basketball tournament is far and away my favorite sporting event of the year. Especially the first weekend — 48 games over four days filled with buzzer beaters and the start of hopeful Cinderella stories. For me, it really doesn’t get any better than that in the sporting world.
Since I’ve been about 8 years old, on the Monday after the tournament schedule is released, I spend far too much time filling out my predictions. Doing a deep dive into all 64+ teams and running through a world of different scenarios, normally filling out half a dozen brackets before settling on one final version. Through the years I’ve become more analytical with my predictions. Below are three non-obvious takeaways from my years of doing this.
1. Use adjusted efficiency margins instead of seeding
I’ve come to rely heavily on Ken Pomeroy’s college basketball ratings to support or refute my own hunches. Historically speaking, his ratings have stronger predictive power compared to the official tournament seeding.
At a high top level, he attributes an adjusted efficiency margin (AdjEM) to each team. From Ken Pomeroy himself:
AdjEM is the difference between a team’s offensive and defensive efficiency. It’s simply subtraction. Even your dog can do it. It represents the number of points the team would be expected to outscore the average D-I team over 100 possessions.
Ken Pomeroy
Teams who make it into the tournament typically have a AdjEM between +5 and +35. A 1-seed’s AdjEM tends to be around +30, a 4-seed’s around +20 to +24, and an 8-seed’s around +14 to +20. Obviously AdjEM doesn’t always match up perfectly with seeding, and that’s good for us. We gain some advantage when most of the world is looking at seeding and we’re looking at the AdjEM ratings and their superior predictive power. Below is a table which shows the estimated win probability of a team with a given AdjEM differential.
The first thing I do when I print out the new year's bracket is write each team's overall AdjEM ranking next to their official seeding. It's a great way to spot potential upsets and get a good sense of all 68 teams pretty quickly.
2. Your picks should be path dependent
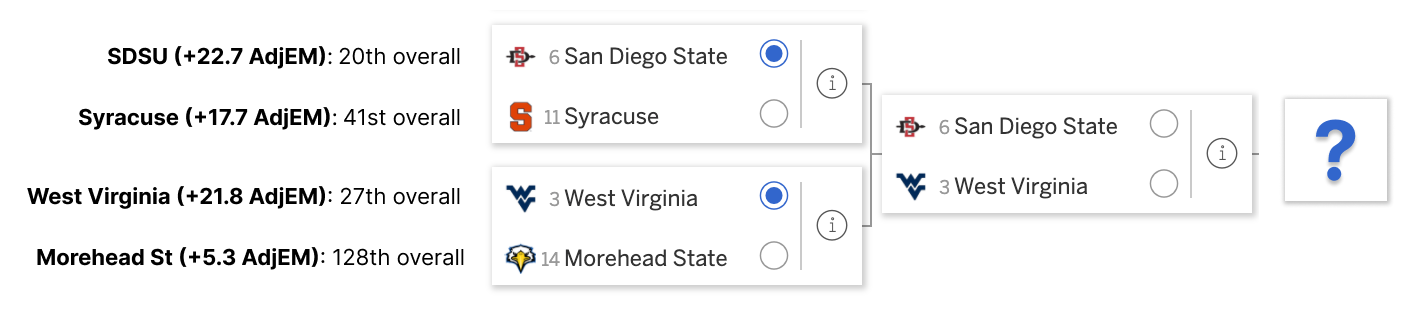
The above is from the Midwest region of the 2021 NCAA tournament. The rankings on the left are based on the adjusted efficiency margin standings as described above.
The most likely second round matchup is San Diego State vs West Virginia. Of those two teams, the AdjEM ratings suggest San Diego State is the better team. In fact, using our rankings San Diego State has about a 53% chance to win a matchup between the two teams. 53% to 47% isn’t a huge margin by any means, but I’ll take 53% all day when it comes to making predictions.
So, we should pick San Diego State to win, right?
Here’s where path dependence comes into play. We should be picking the team most likely to emerge into that winner’s spot of the four teams, not which team is more likely to win the SDSU-WVU matchup. Because West Virginia has a far easier matchup in the first-round vs Morehead State (compared to SDSU’s matchup against Syracuse), West Virginia is actually the better pick here, despite not being the better team.
2.1 It's a tough year to be a #1 seed
As the tournament progresses, this path dependency effect compounds. This is a particularly difficult year to be a #1 seed, and a particularly easy year for #2 seeds. Take a look at the average AdjEM rankings compared to tournament seeds.
Due to the 64 team tournament structure, as a 1-seed, you’ll likely face off against the 8 or 9-seed in the second round followed by the 4 or 5-seed in the third round. As a 2-seed, you’ll play the 7 or 10-seed in the second round and the 3 or 6-seed in the third round. According to AdjEM rankings, both the 4 and 5-seed teams are, on average, better than the 3-seed teams. Furthermore, the 8 and 9-seed teams are, on average, better than the 7-seed teams. The South region is particularly brutal for Baylor, paired in a region with a 9th seeded Wisconsin (10th overall in AdjEM), a 4th seeded Purdue (13th in AdjEM), and a 5th seeded Villanova (12th in AdjEM). As a result, Baylor, even though they are ranked higher in AdjEM, are less likely to make it to the Sweet 16 and Elite 8 compared to 2nd seeds Houston and Iowa, and their easier respective paths.
3. Pick more upsets in bigger pools
Now we don’t want to follow AdjEM ratings exactly. What fun would that be! In fact, it’s not even a winning strategy. Interestingly, our strategy should change based on the number of people we are competing with in our “tournament pool”.
Your final predictions for your family competition of 6 people should be different than your predictions in your co-worker pool of 30 people. Picking chalk (choosing the favorite to win every game) will win a pool of 6 about 25% of the time (an improvement of nearly 50% over the default 1/6 = 16.7% odds). Picking chalk in a pool of 30 will win about 1.6% of the time (less than 50% of the default 1/30 = 3.3% odds).
The above calculations assume that each game’s win predicted win probability falls along a normal distribution centered at 50% with a standard deviation of 25%, which is roughly the distribution across all games. It also assumes that, given Michigan has an 80% chance to beat Clemson, 80% of predictors will choose Michigan. This again, is roughly, but not precisely correct. Regardless of exact numbers, the general principal stands.
This makes intuitive sense. Larger pools will tend to have a higher winning score — you will need to pick more games right that other people picked incorrectly to win. There isn’t a hard and fast rule for doing this, but combining with the path dependency logic above, it makes good sense to predict upsets against teams with particularly difficult paths. For instance, you might pick Ohio State over Baylor in the Elite 8 matchup because of Baylor’s difficult path — there’s a good chance it will be Wisconsin or Villanova or Purdue or North Carolina playing in that game in place of Baylor.
Aside from that, I like to have some fun with it. This is where you can put your personal stamp on your predictions and give yourself some real rooting interests that makes watching more exciting. I keep an eye out for teams that shoot a lot of 3s – they have a higher chance to upset or be upset given the huge difference between a hot shooting day and an ice-cold day (see Jimmer Fredette at BYU and Steph Curry at Davidson). I also like teams coming off good conference tournaments, I feel like they’re peaking at the right time (see Kemba Walker’s UConn). A lot of people like 12 vs 5 upsets, at least one has happened 16 of the past 19 tournaments, and in 36% of the matchups overall. And as a Maryland fan and alum, I can whole heartedly say that picking them to lose early in any given year is a good bet 🙈
We're just getting started.
Subscribe for more thoughtful, data-driven explorations.